The infrastructure reality check
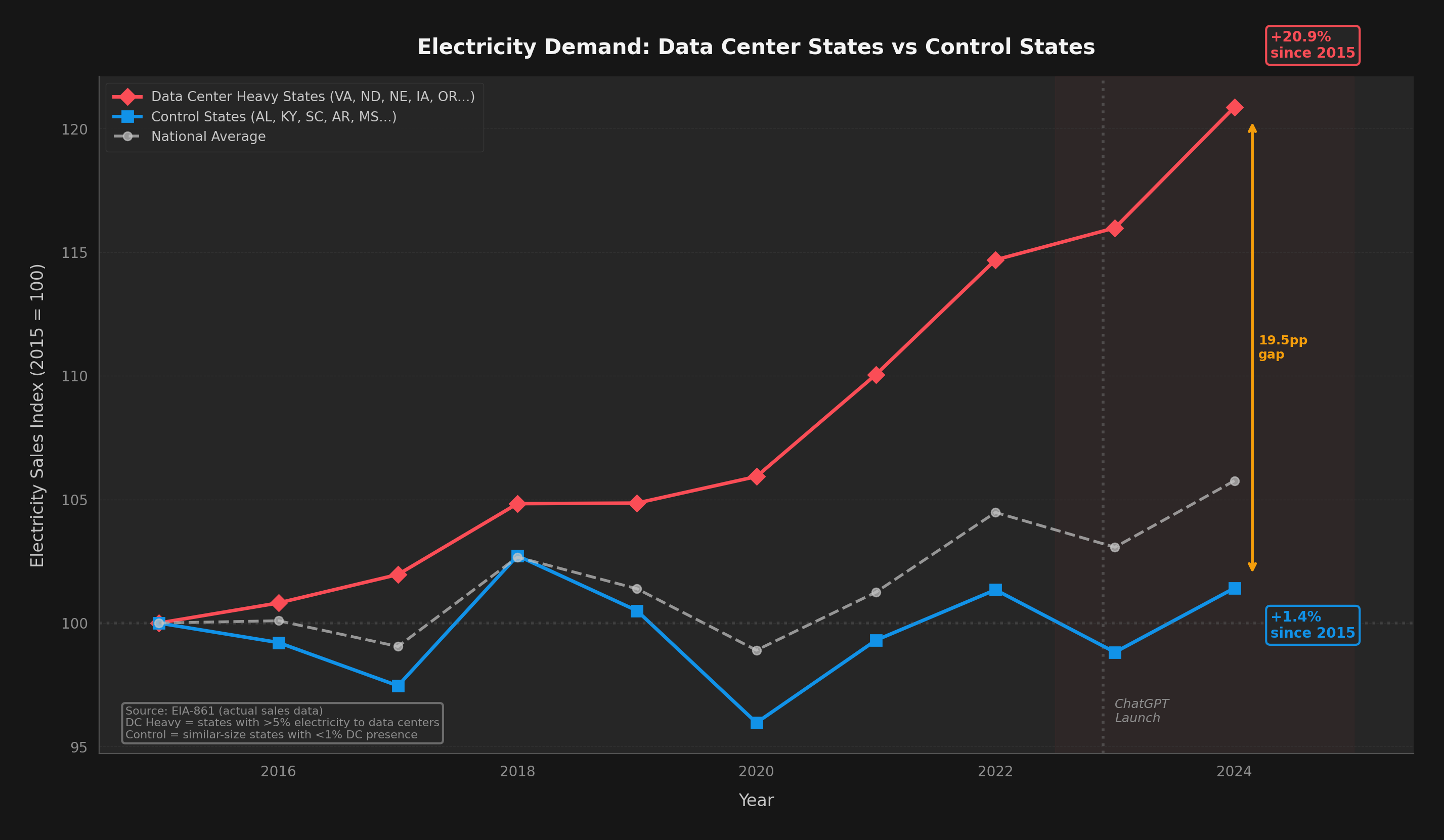
PJM, the grid operator covering Virginia and 12 other states (65 million people), initially projected a 6-gigawatt shortfall below reliability requirements by 2027. After stricter data center vetting, PJM revised this to approximately 2.6 GW in late 2025 — still a significant gap. Coal plants in Kansas City and West Virginia have already delayed closures to meet AI-driven demand. Data center water consumption is projected to double or quadruple by 2028, reaching 150-280 billion liters annually in the US alone.
01
Measure energy per outcome, not tokens
Track electricity cost per deployed feature, not per token. The METR study showed developers are 19% slower with AI despite thinking they're faster. If your agents use 10x more tokens but ship the same output, that's a Jevons problem.
02
Plan for hardware transitions
Blackwell delivers 2-3x real-world efficiency gains. Rubin claims 10x more. Build your inference infrastructure to swap hardware generations quickly. Efficiency gains only help if you deploy them.
03
Consider smaller, fine-tuned models
The SERA paper achieved 54.2% on SWE-Bench for $2,000 in training costs. For many use cases, a fine-tuned 7B model running on-premise uses 100x less energy than a frontier API call. Not every task needs Opus.
04
Watch your data center geography
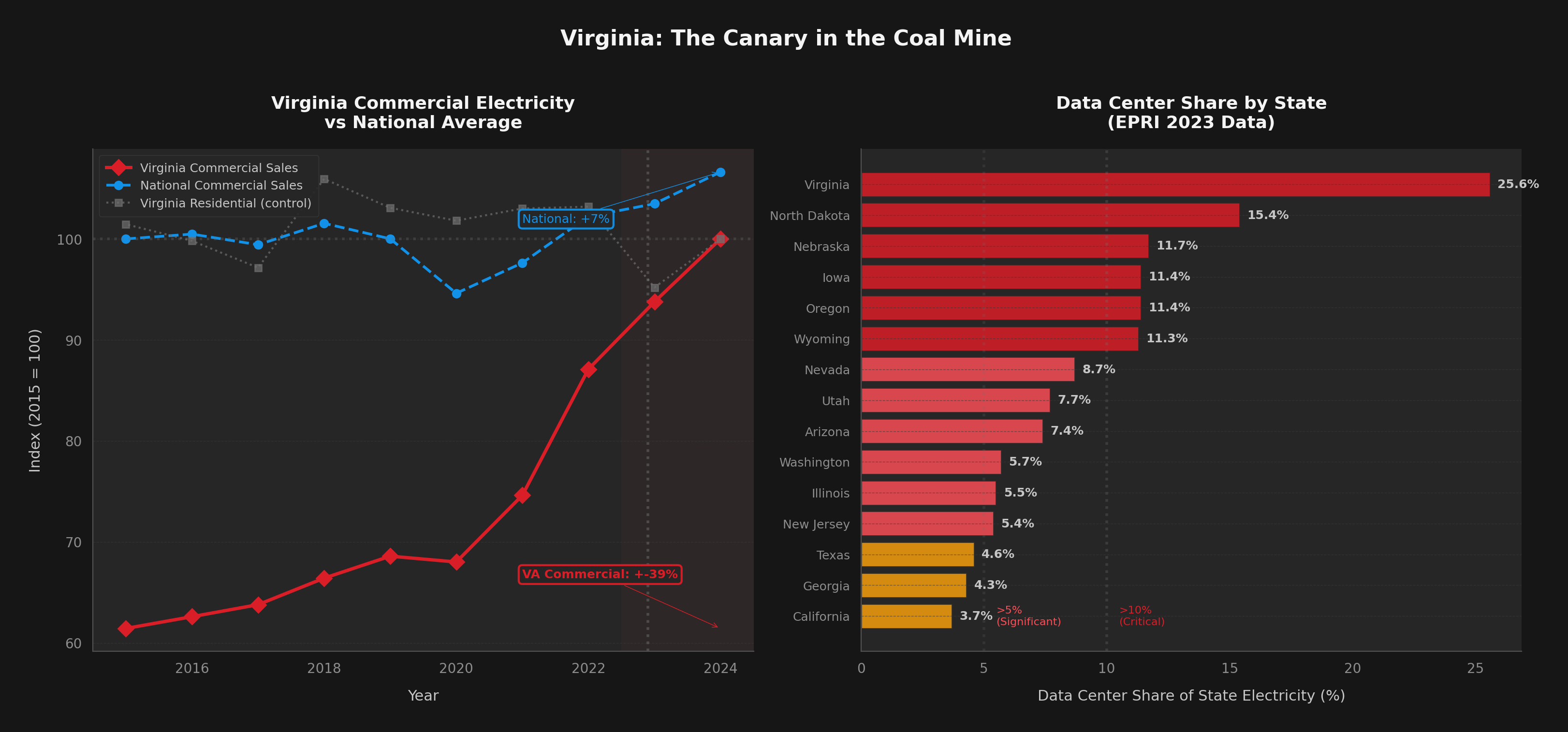
If your cloud provider's primary region is in Virginia, Texas, or Oregon, factor in rising electricity costs and potential capacity constraints. Diversify regions. Virginia's capacity auction prices spiked 833%.
05
Budget for the Jevons effect
When you roll out agentic AI, expect 5-10x the compute budget of chat-based AI. A single Claude Code session can consume 2M tokens. Multiply by your engineering team size. Then multiply by continuous integration.
06
Treat energy as a first-class constraint
Energy is becoming the binding constraint on AI scaling — not model quality, not talent, not data. Companies that optimize for energy efficiency will have a structural cost advantage by 2028.
The Bottom Line
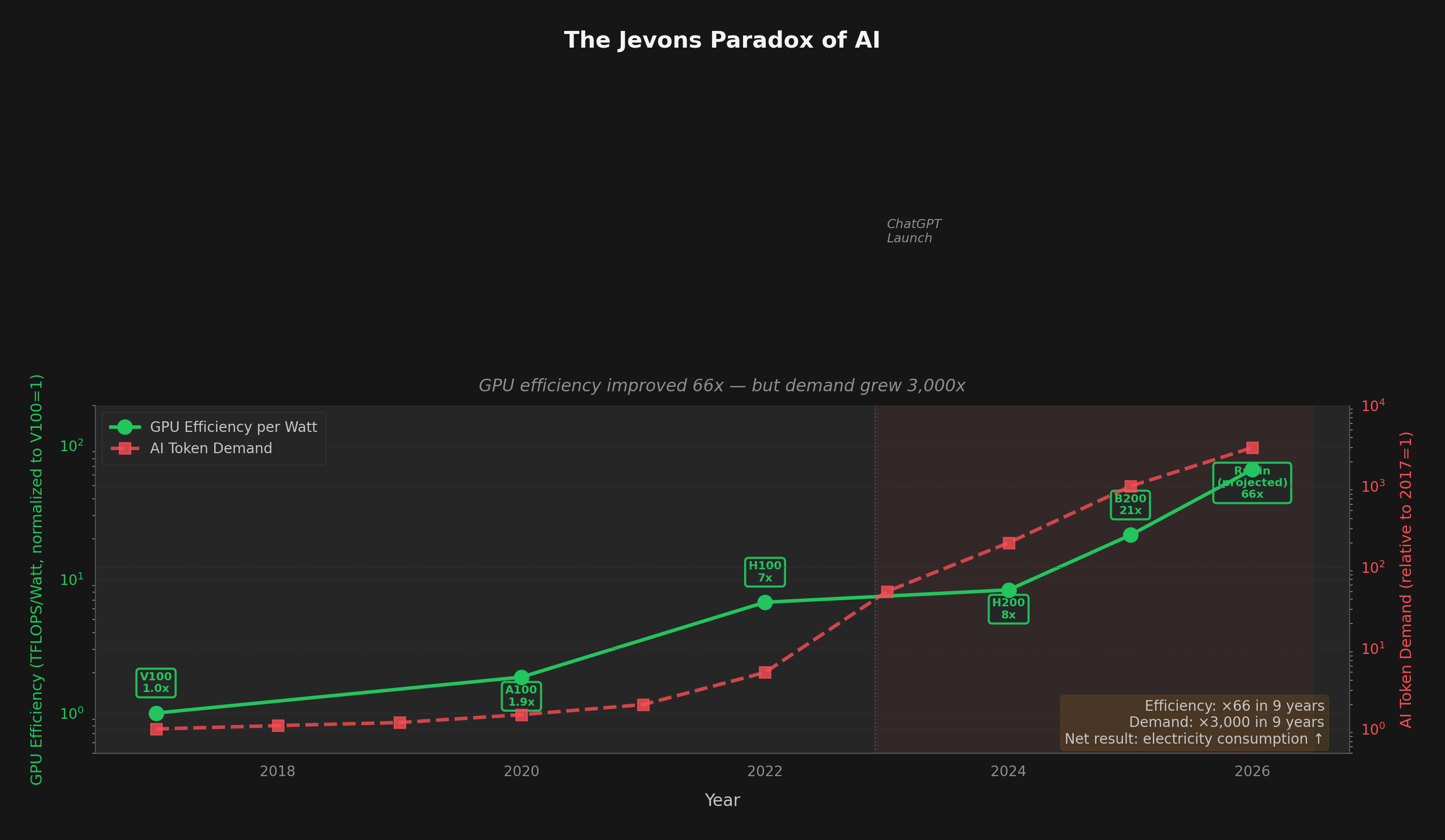
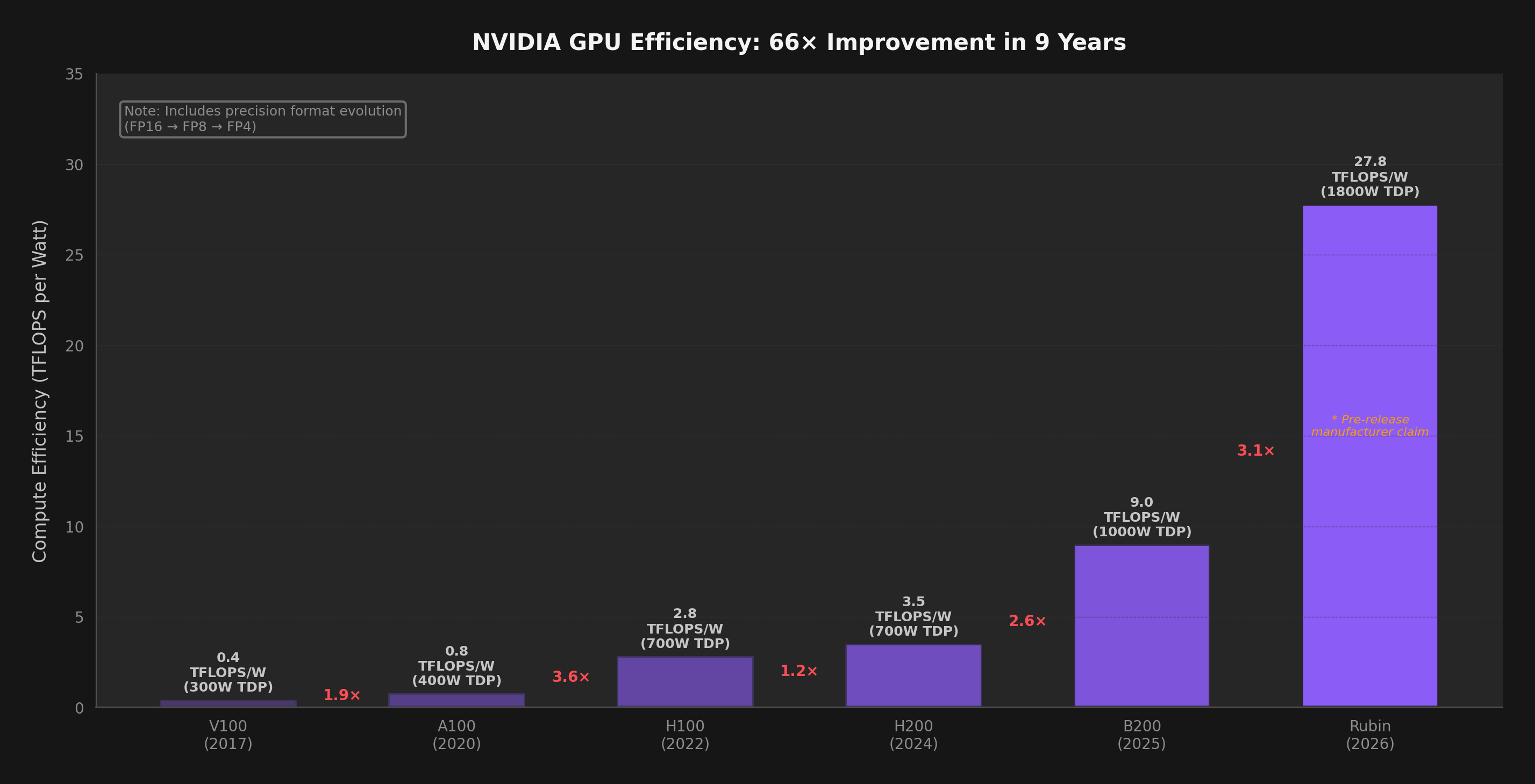
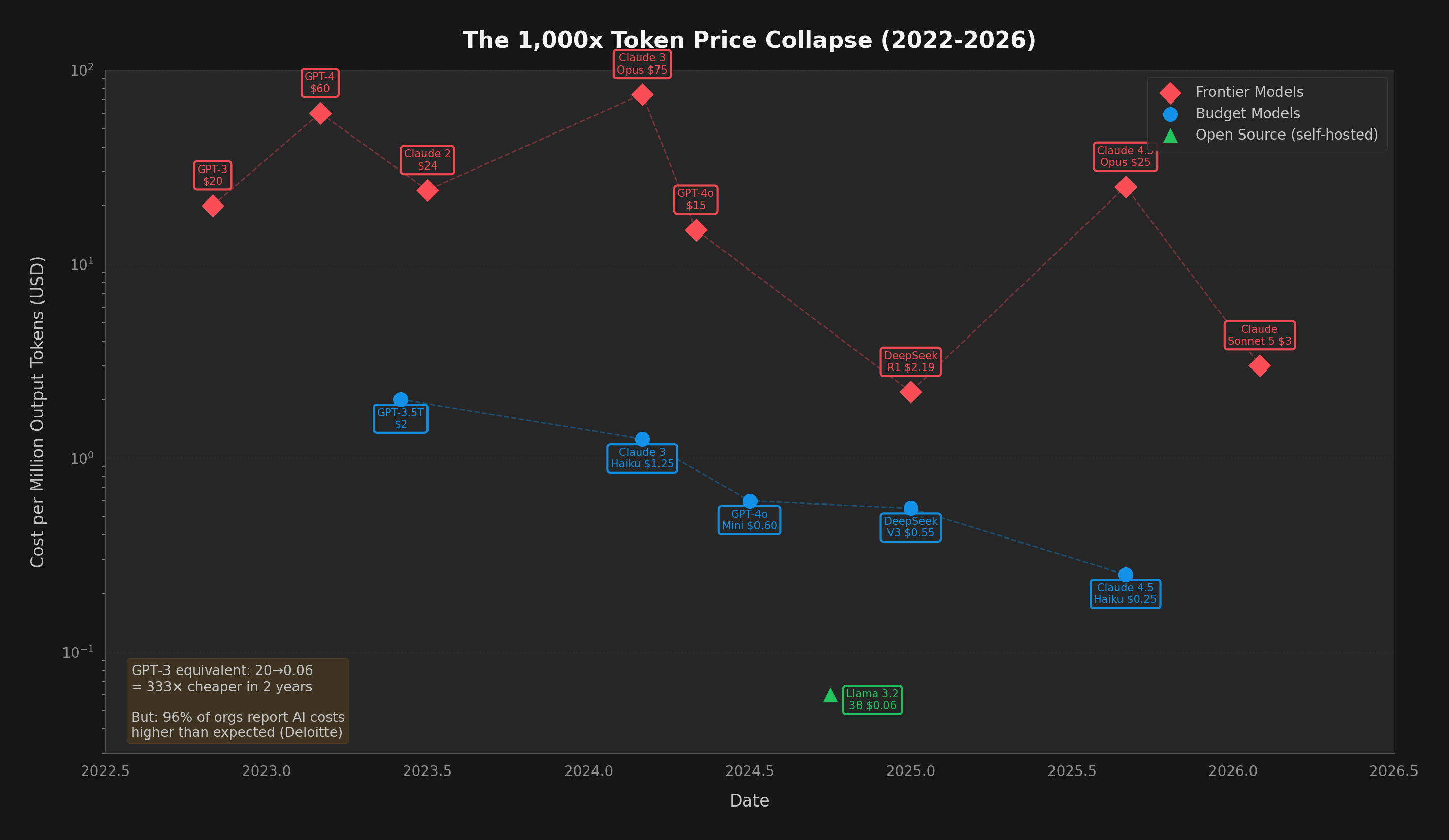
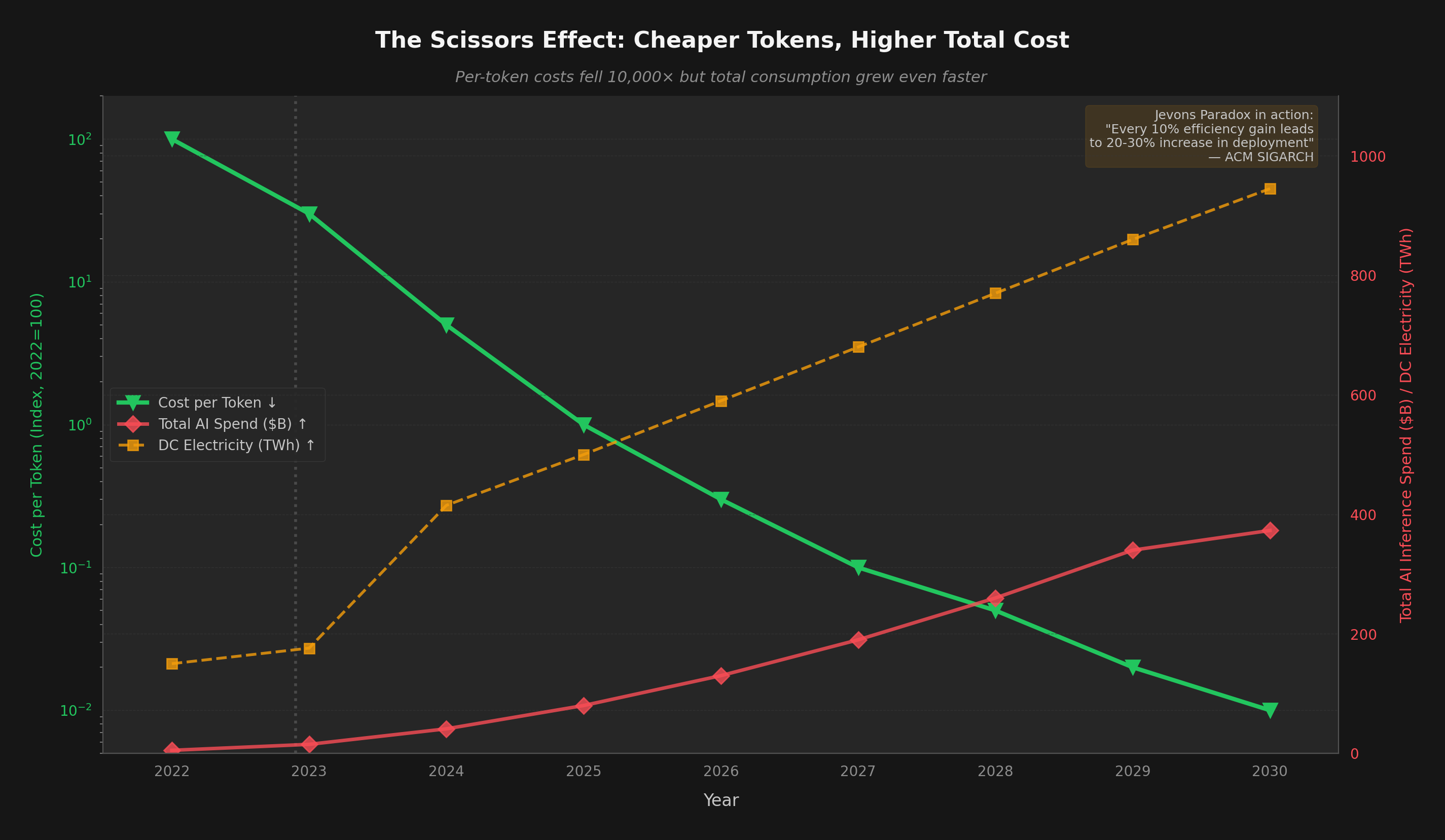
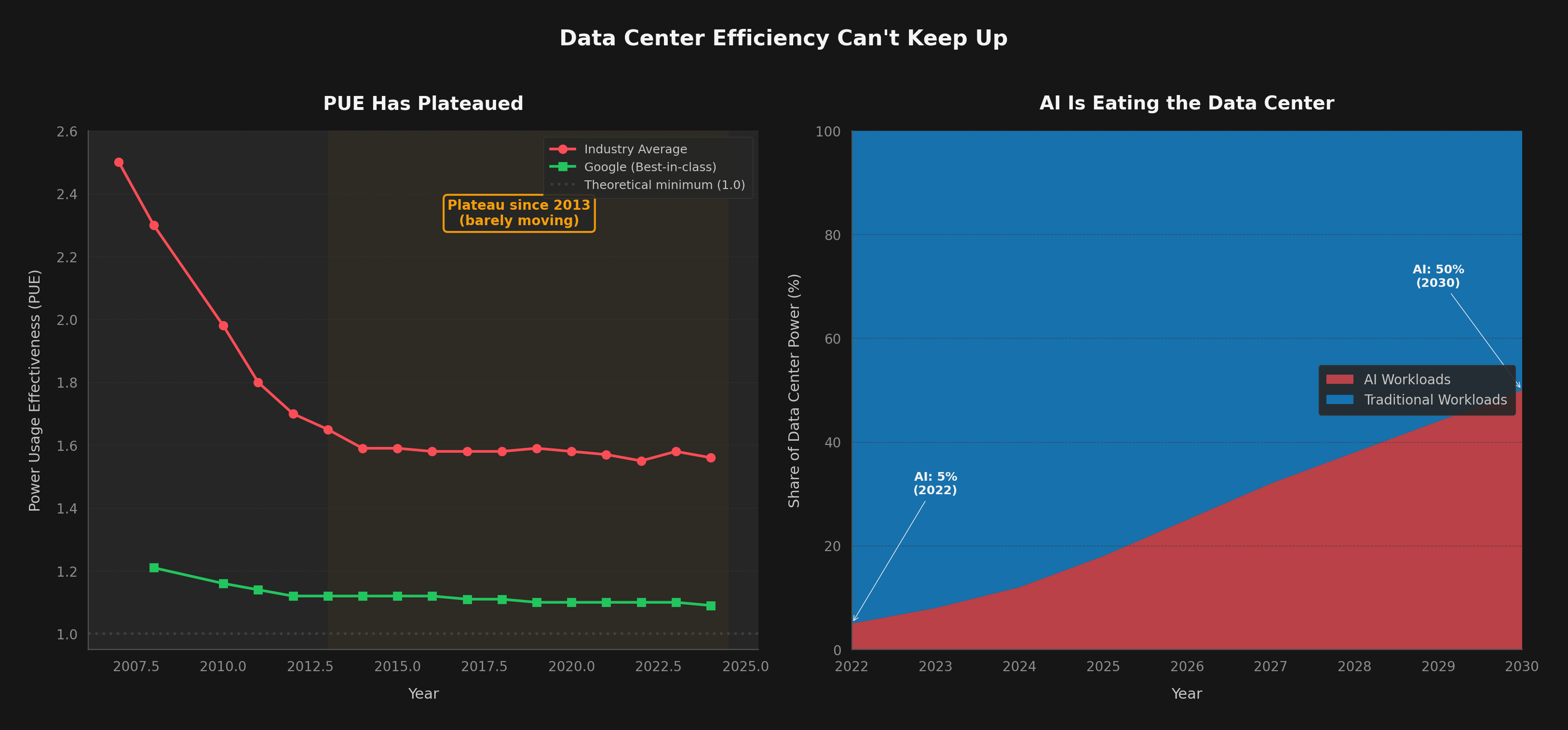
Hardware engineers are doing extraordinary work. GPU silicon improved ~66x in compute per watt over 9 years (including the shift from FP16 to FP4 precision). But that's only part of the story — algorithmic gains (quantization, MoE, distillation) contributed another ~5x, and hyperscaler economies of scale plus competitive pricing pressure added ~3x more. Multiply them together: 66 × 5 × 3 ≈ 1,000x total reduction in the cost to run a token. NVIDIA's Blackwell and Rubin, Google's Ironwood TPU, and AMD's MI355X represent genuine breakthroughs.
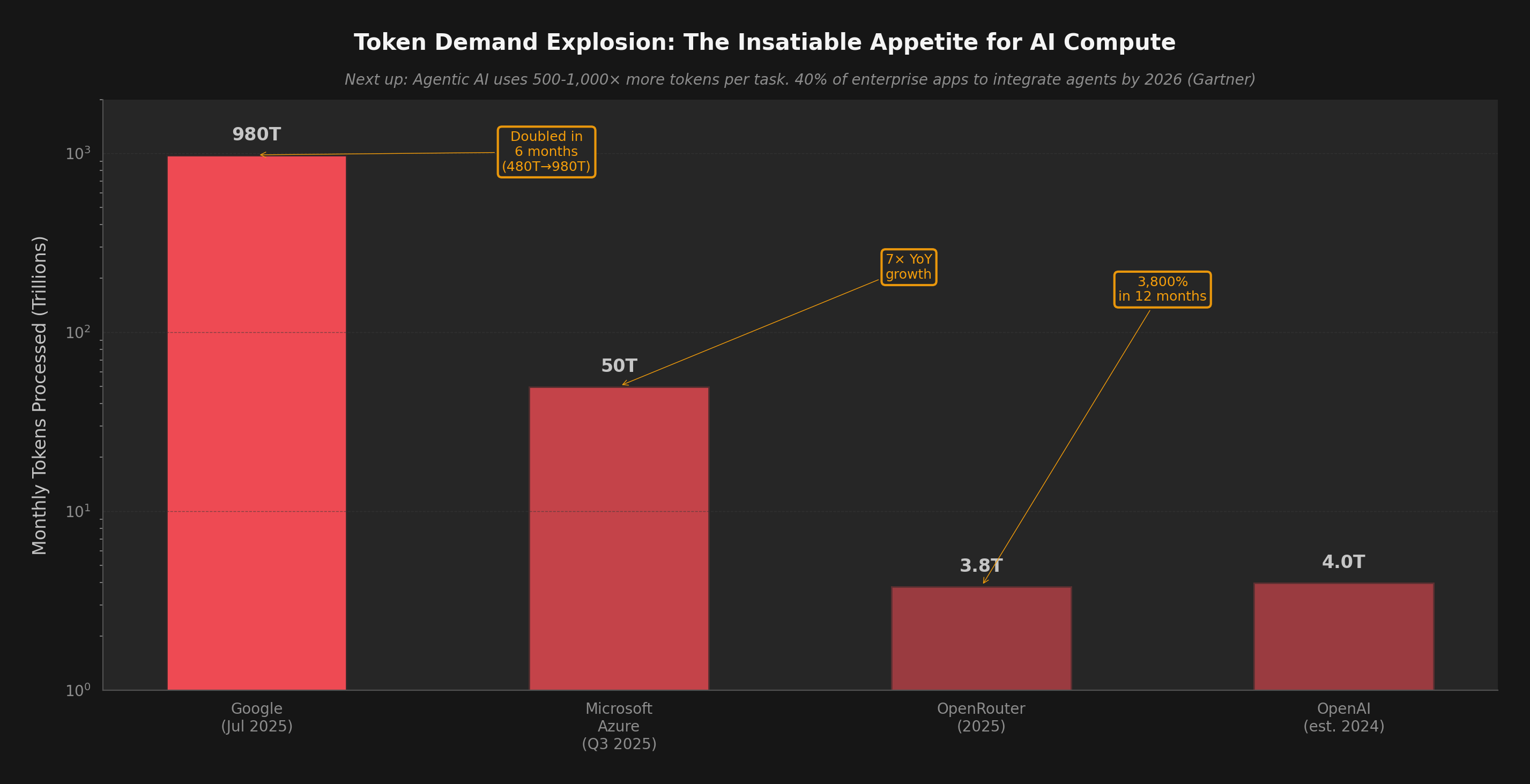
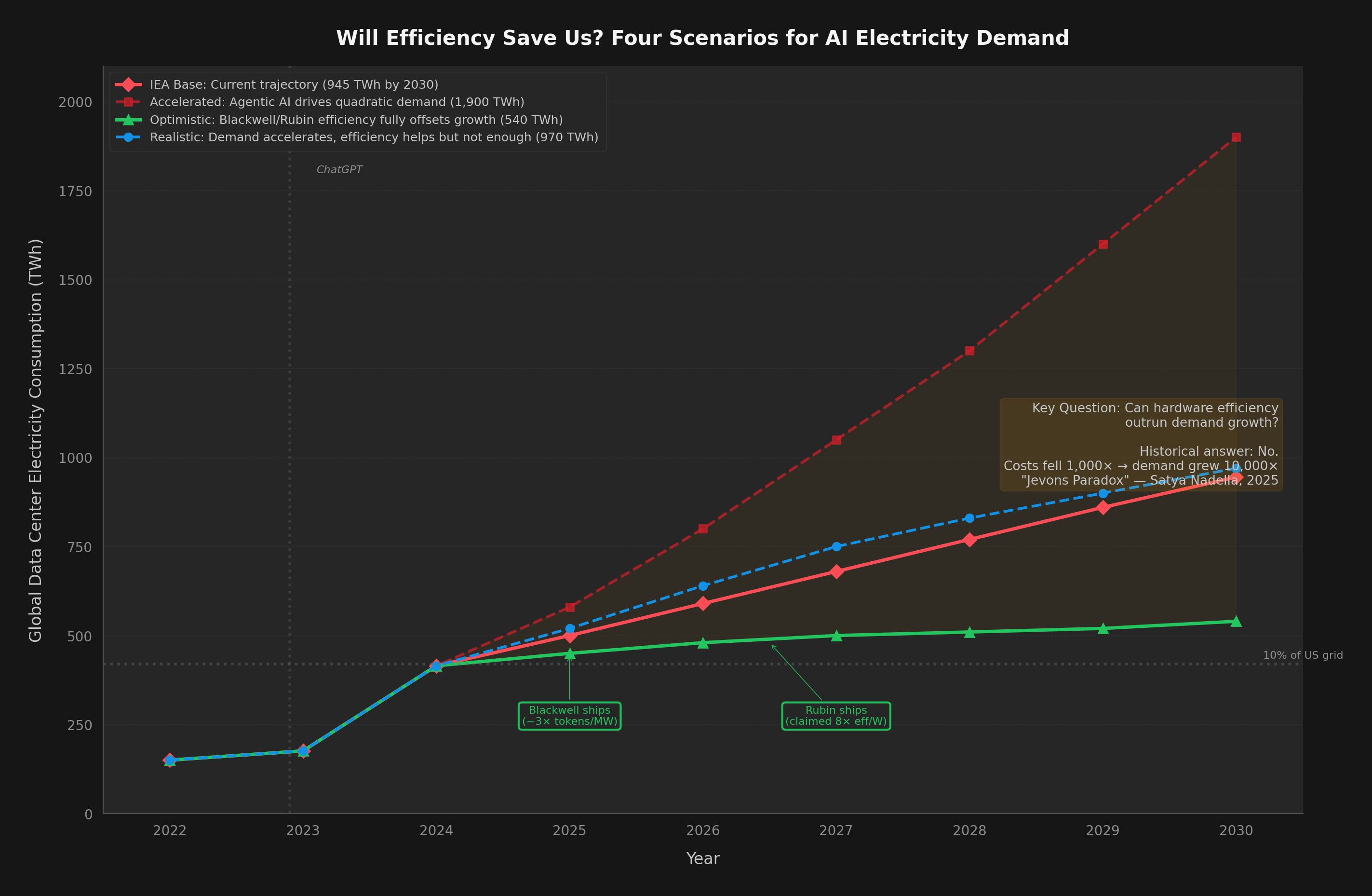
But efficiency alone cannot solve the AI electricity crisis. The historical pattern is unambiguous: every time we make AI cheaper and faster, we use dramatically more of it. That 1,000x cost reduction unleashed 10,000x more demand. The grid feels the net, not the per-unit improvement.
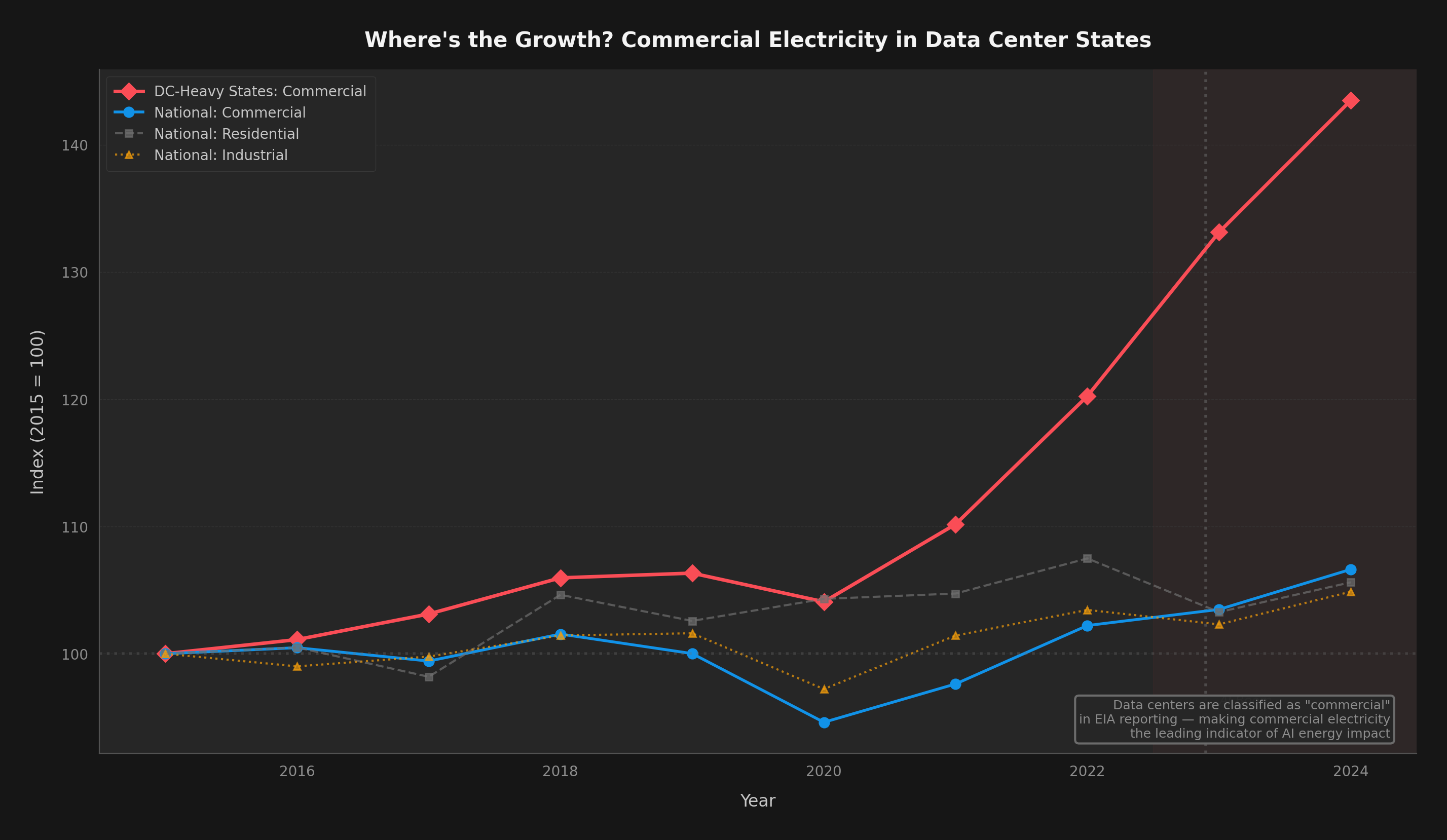
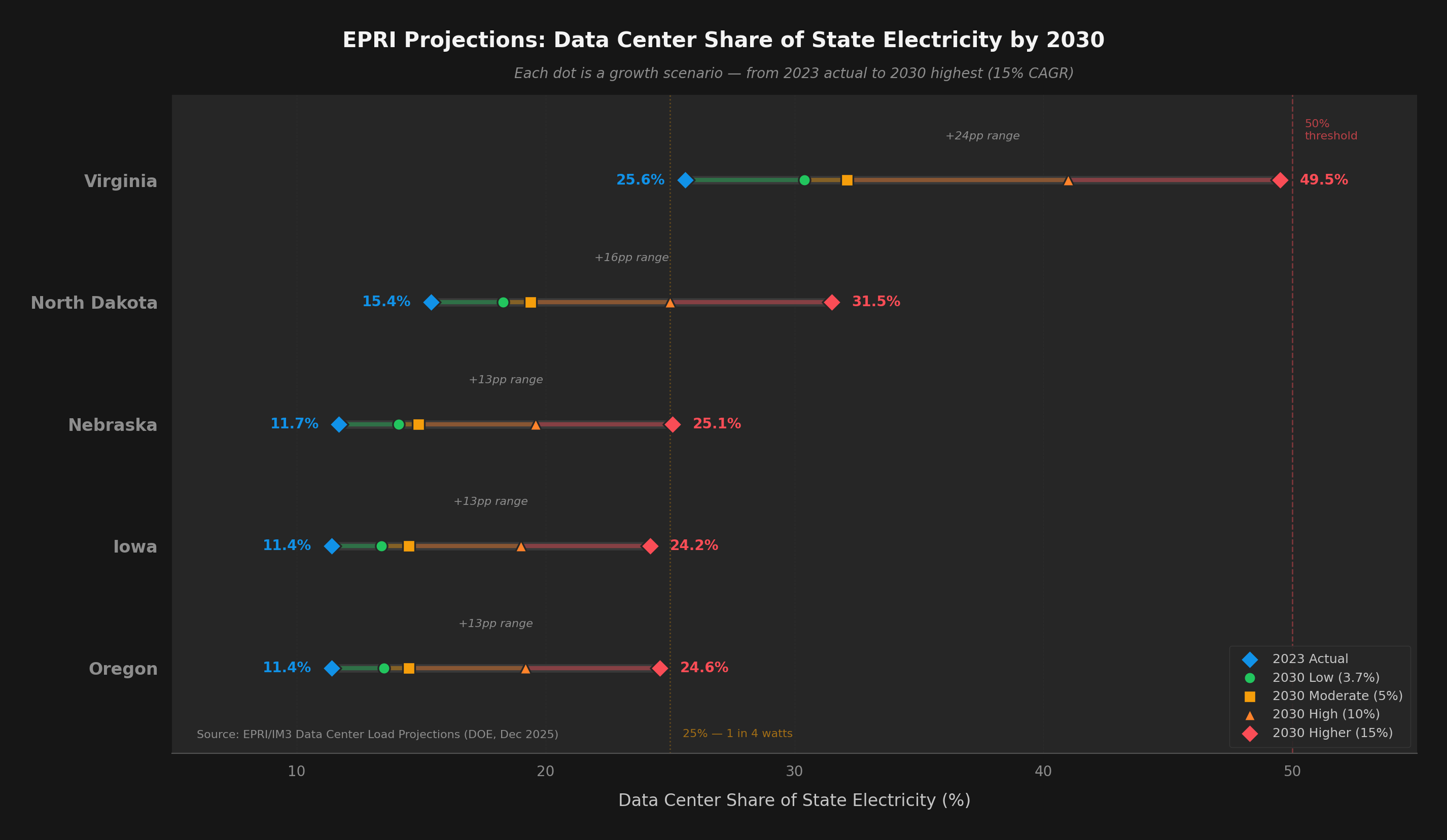
The states where data centers are already concentrated — Virginia, Oregon, Iowa, North Dakota, Nebraska — are living previews of what the rest of the country will face by 2030. Virginia's grid didn't plan for 25% data center load. Neither did anyone else's.
"We are entering a rite of passage, both turbulent and inevitable, which will test who we are as a species."
— Dario Amodei, CEO Anthropic, "The Adolescence of Technology" (January 2026)
The companies that thrive in this environment won't be the ones with the most GPUs. They'll be the ones who understand that intelligence is becoming abundant, but energy is becoming scarce — and plan accordingly.