Part 2
The Frontier Four: Each Model Has a Superpower
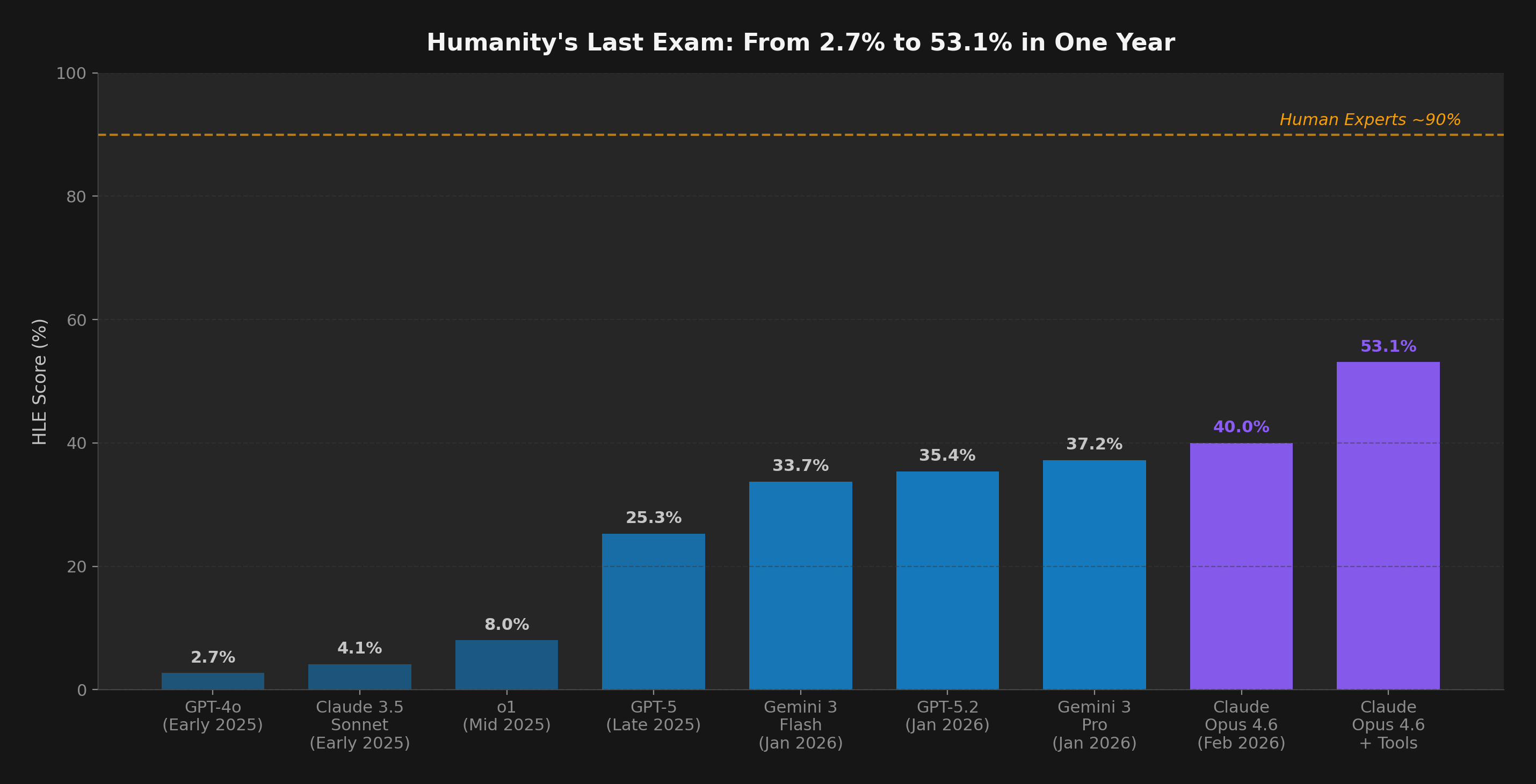
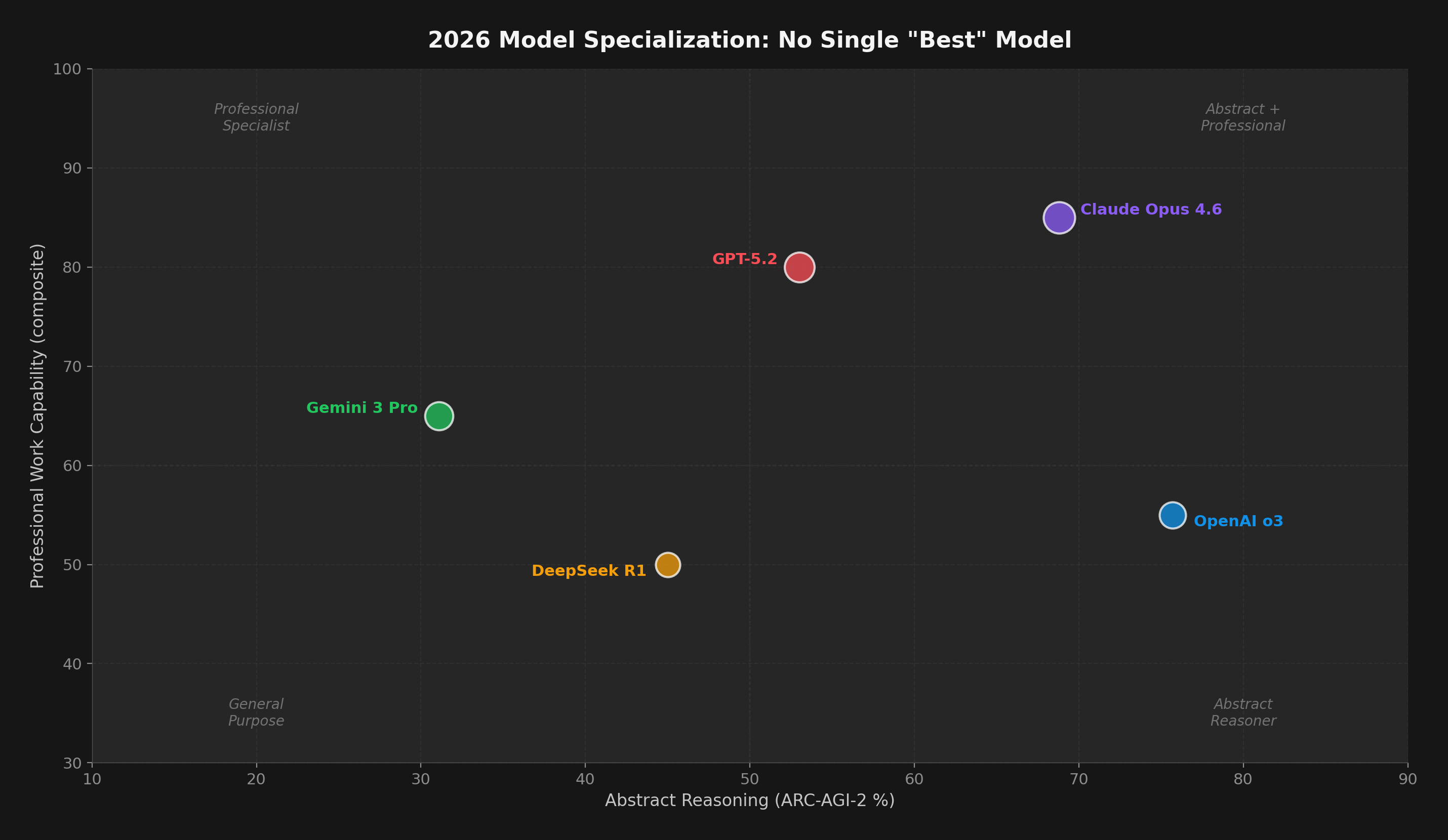
The most striking finding of early 2026 is that no single model dominates every benchmark. Instead, each frontier model has carved out a domain of excellence — and the choice of model now depends entirely on the task.
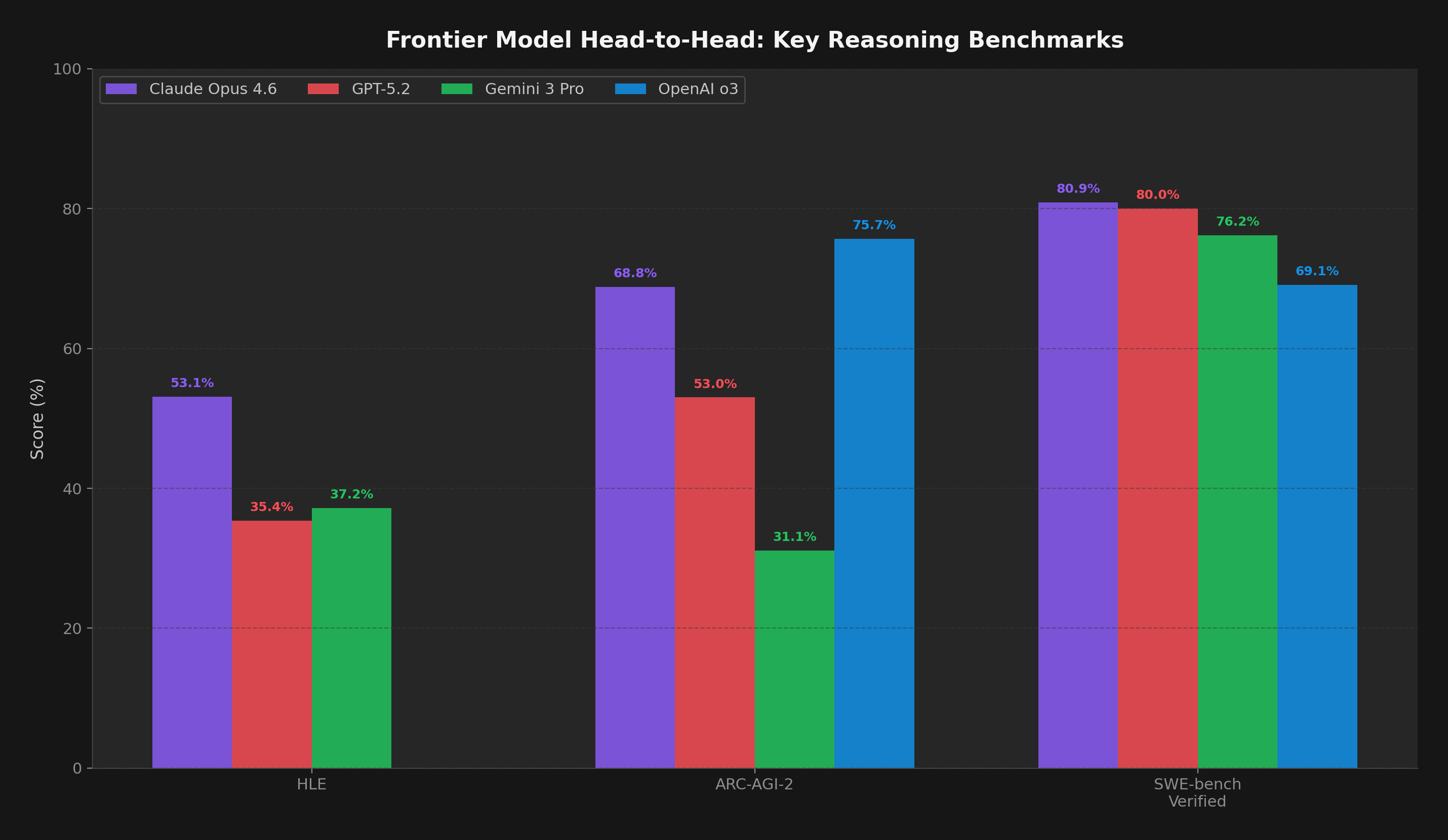
Figure 2: Head-to-head on three shared benchmarks. Claude Opus 4.6 leads HLE (53.1%) and is competitive on SWE-bench. OpenAI o3 leads ARC-AGI-2 (75.7% standard compute; 87.5% on ARC-AGI-1 high compute). No model wins everywhere.
| Model |
Best At |
Key Score |
Weakness |
| Claude Opus 4.6 |
Agentic coding, professional work |
Terminal-Bench: 65.4% (SOTA) |
Abstract reasoning (vs o3) |
| GPT-5.2 |
Pure mathematics, abstract reasoning |
FrontierMath: 40.3% (10x prev.) |
Professional work (vs Opus) |
| Gemini 3 Pro |
Multimodal science, broad excellence |
GPQA Diamond: 91.9% |
ARC-AGI-2 (31.1%) |
| OpenAI o3 |
Abstract visual reasoning |
ARC-AGI-1: 87.5% (high compute) |
Extremely expensive per puzzle |
Claude Opus 4.6: The Professional's Model
Released February 5, 2026, Opus 4.6 introduced several firsts: a 1 million token context window for Opus-class models, "Adaptive Thinking" that dynamically adjusts reasoning depth across four effort levels, and "Agent Teams" enabling multiple Claude instances to collaborate on the same project.
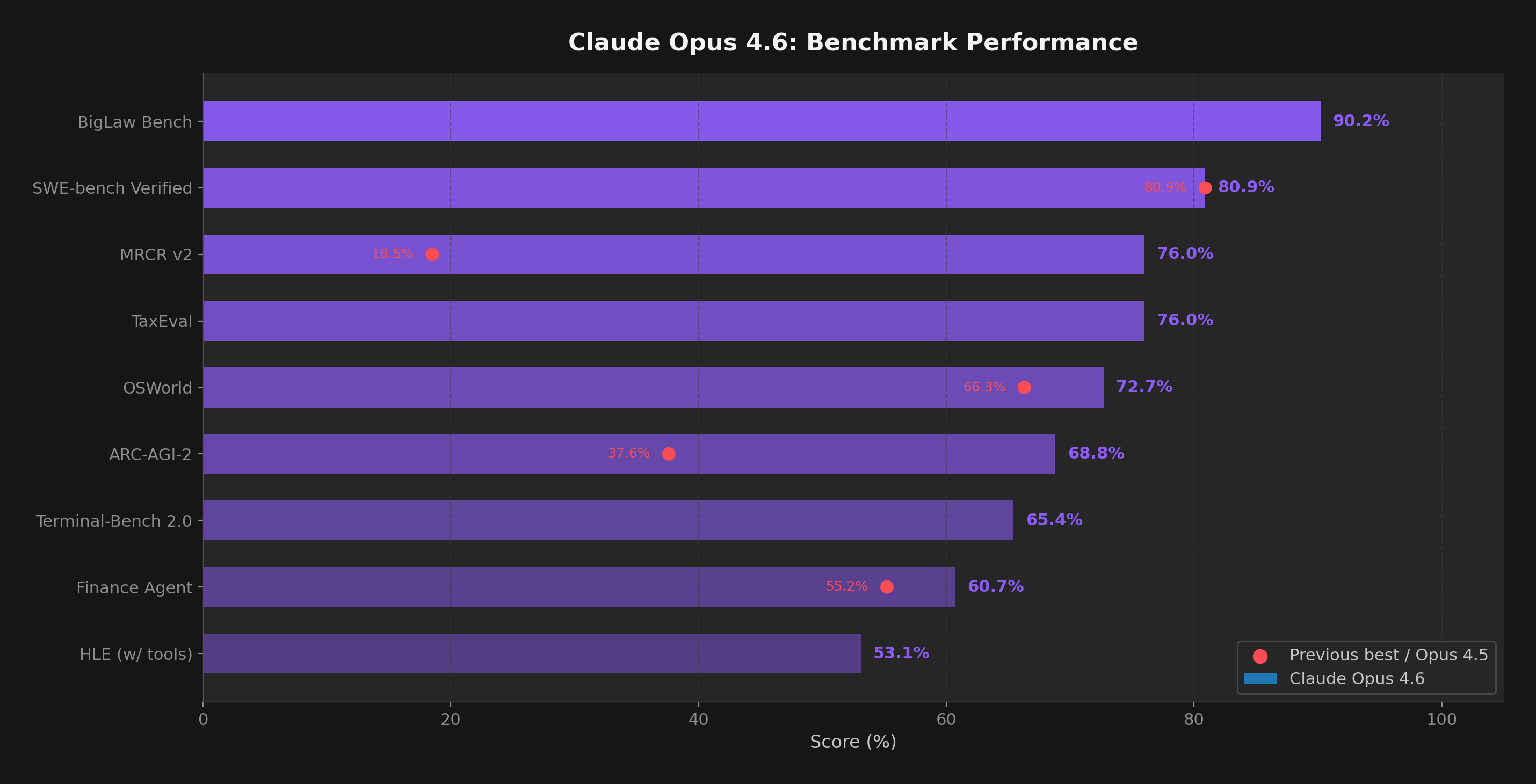
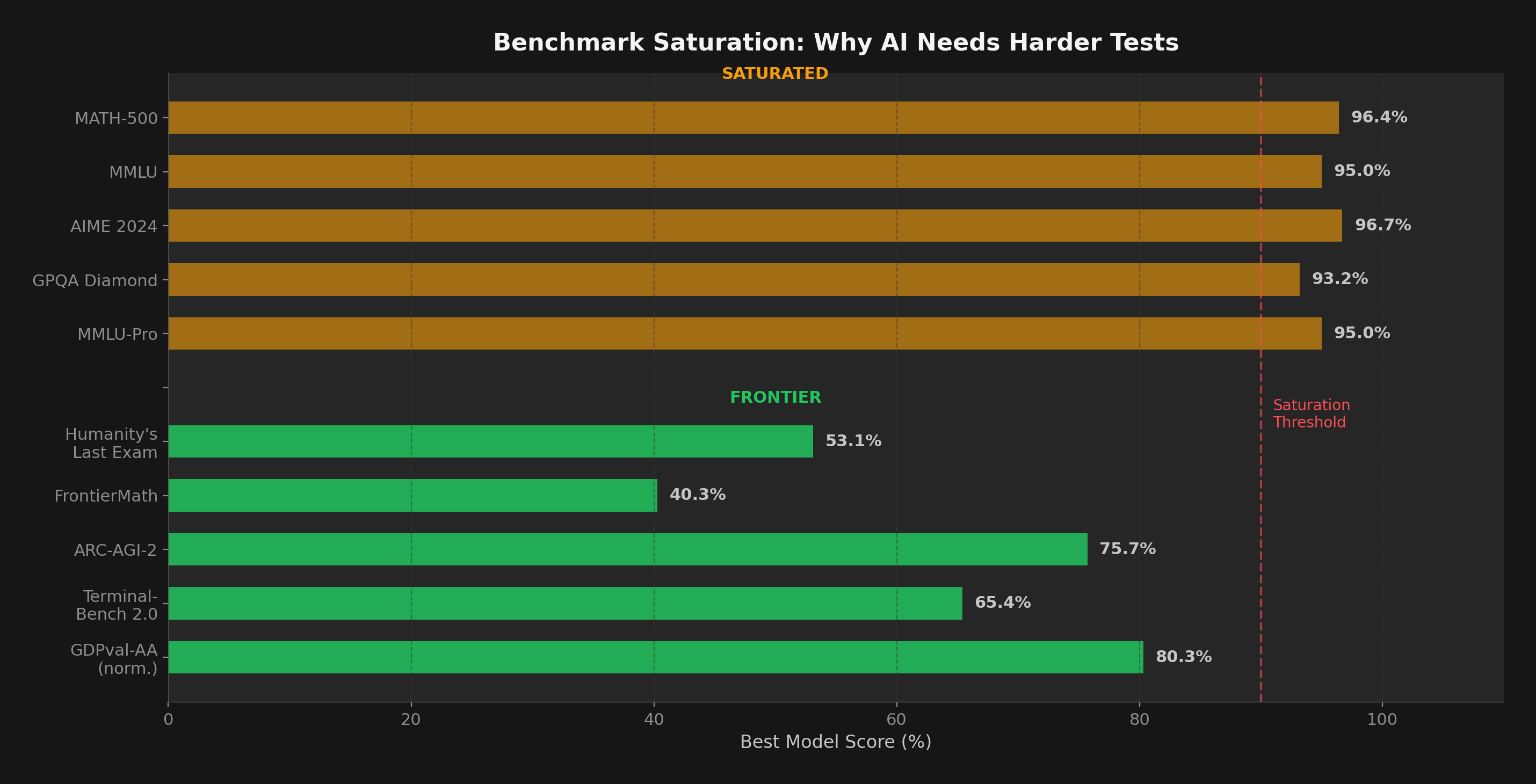
Figure 3: Claude Opus 4.6 benchmark performance with previous best scores (red dots) where available. Notable jumps: ARC-AGI-2 improved 83% over Opus 4.5, MRCR v2 jumped from 18.5% to 76%.
On GDPval-AA — a benchmark measuring real-world professional tasks across 44 knowledge work occupations — Opus 4.6 scored 1606 Elo, beating GPT-5.2's 1462 by 144 points. That translates to winning roughly 70% of head-to-head comparisons on finance, legal, and other professional tasks.
The model also demonstrated its capabilities in two dramatic demonstrations: 16 parallel Claude instances autonomously built a C compiler over 2 weeks (consuming 2 billion input tokens), and Opus 4.6 discovered 500+ zero-day vulnerabilities in open-source code using "out-of-the-box" capabilities.
"Claude Opus 4.6 excels on the hardest problems. It shows greater persistence, stronger code review, and the ability to stay on long tasks where other models tend to give up."
— Michael Truell, Co-founder of Cursor
GPT-5.2: The Mathematician
OpenAI's GPT-5.2 achieved a paradigm shift in mathematical reasoning. On FrontierMath — a benchmark of 350 original, unpublished problems requiring PhD-level mathematics — it scored 40.3%. Previous models couldn't break 2%. On AIME (American Invitational Mathematics Examination), GPT-5.2 Thinking achieved a perfect 100%.
GPT-5.2 also scored 77% on FrontierScience Olympiad tasks and 25% on Research tasks — demonstrating capability at the boundary of current scientific knowledge.
OpenAI o3: The Cost-Efficiency Question
o3's 87.5% on ARC-AGI-1 in high-compute mode surpassed the 85% prize threshold — a historic milestone. But at what cost? Some puzzles consumed hundreds of dollars in compute; even in low-compute mode, o3 costs $17–20 per task. Humans solve the same puzzles for roughly $5 each. ARC-AGI's François Chollet has responded by adding efficiency metrics: intelligence = capability + cost-effectiveness. On the harder ARC-AGI-2, o3 scores 75.7% in standard compute.