The Grounding Problem: Why 84% Adoption Doesn't Mean ROI
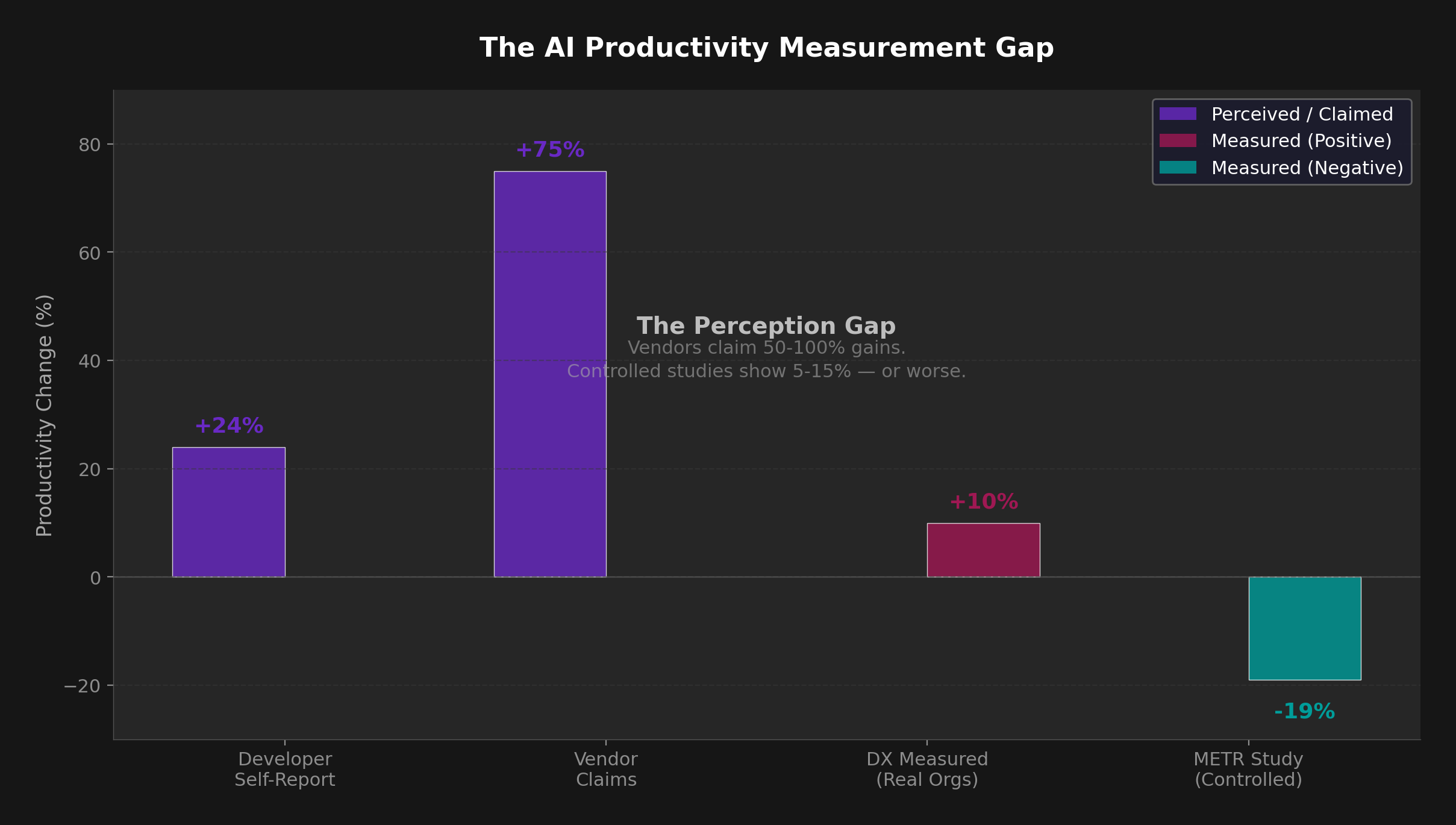
The enterprise AI paradox of 2026 is stark: 84% of developers use AI tools daily, yet only 23% of organizations can measure any ROI from their adoption. CEOs are optimistic, budgets are surging, and developers swear their work is faster. So why doesn't the data match the enthusiasm?
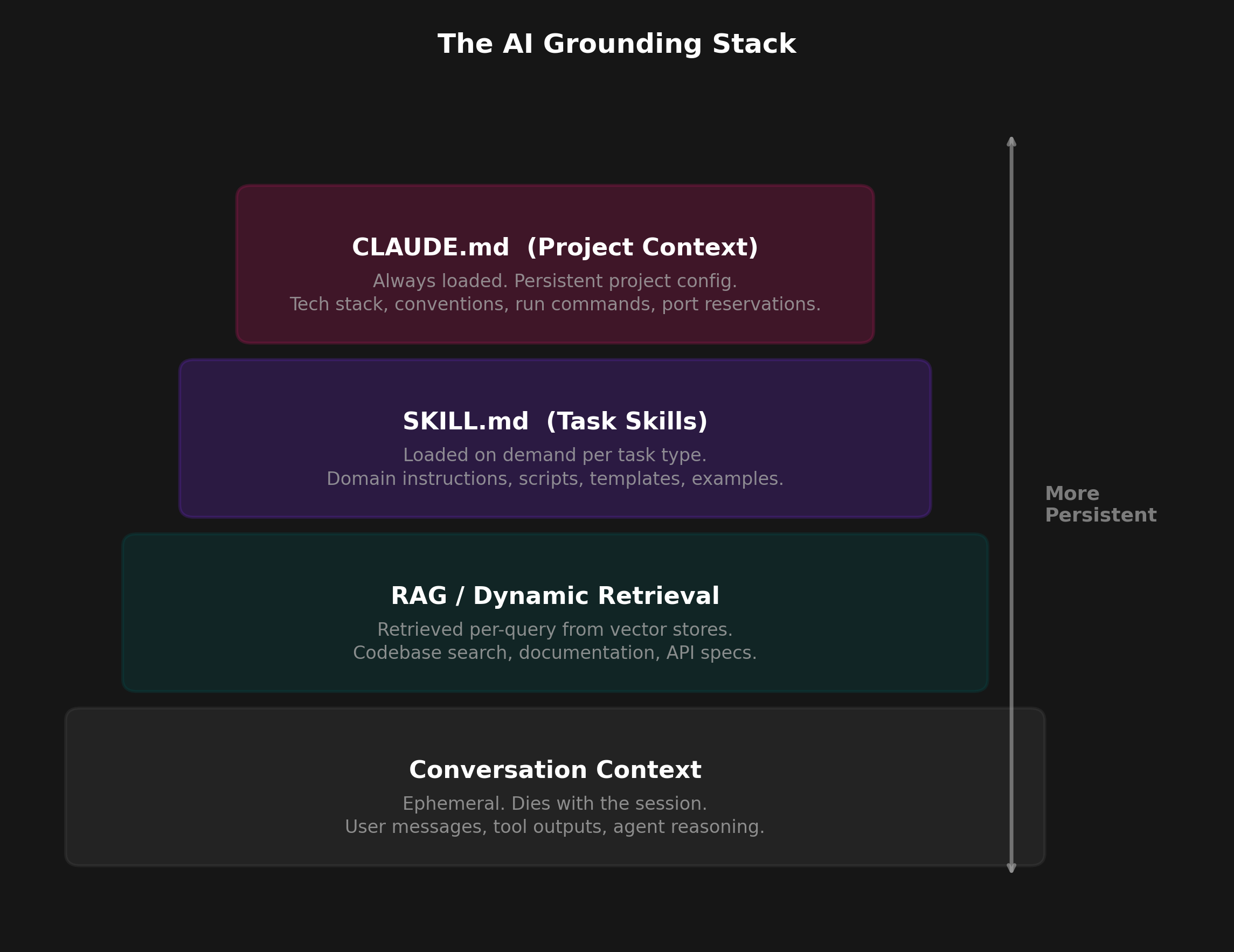
The answer is a grounding problem — giving AI models structured context about your team's conventions, patterns, and workflows. Without it, every AI interaction starts from zero. The model doesn't know your coding standards or deployment workflows. It generates code that "looks right" but fails in review.
A 2026 Microsoft Research study titled "Beyond the Prompt" analyzed 401 GitHub repositories containing instruction files. It identified five recurring themes: Conventions, Guidelines, Project Info, LLM Directives, and Examples. Every high-performing team independently converged on the same structure.
The evidence for structured prompts is strong. The InFoBench benchmark (ACL 2024) introduced the DRFR metric — Decomposed Requirements Following Ratio — to measure how well models follow complex, multi-part instructions. Models consistently score higher when given explicit context and examples. An EMNLP 2025 survey on prompt optimization found that optimized prompts improve correctness by 20-50% compared to baseline approaches.
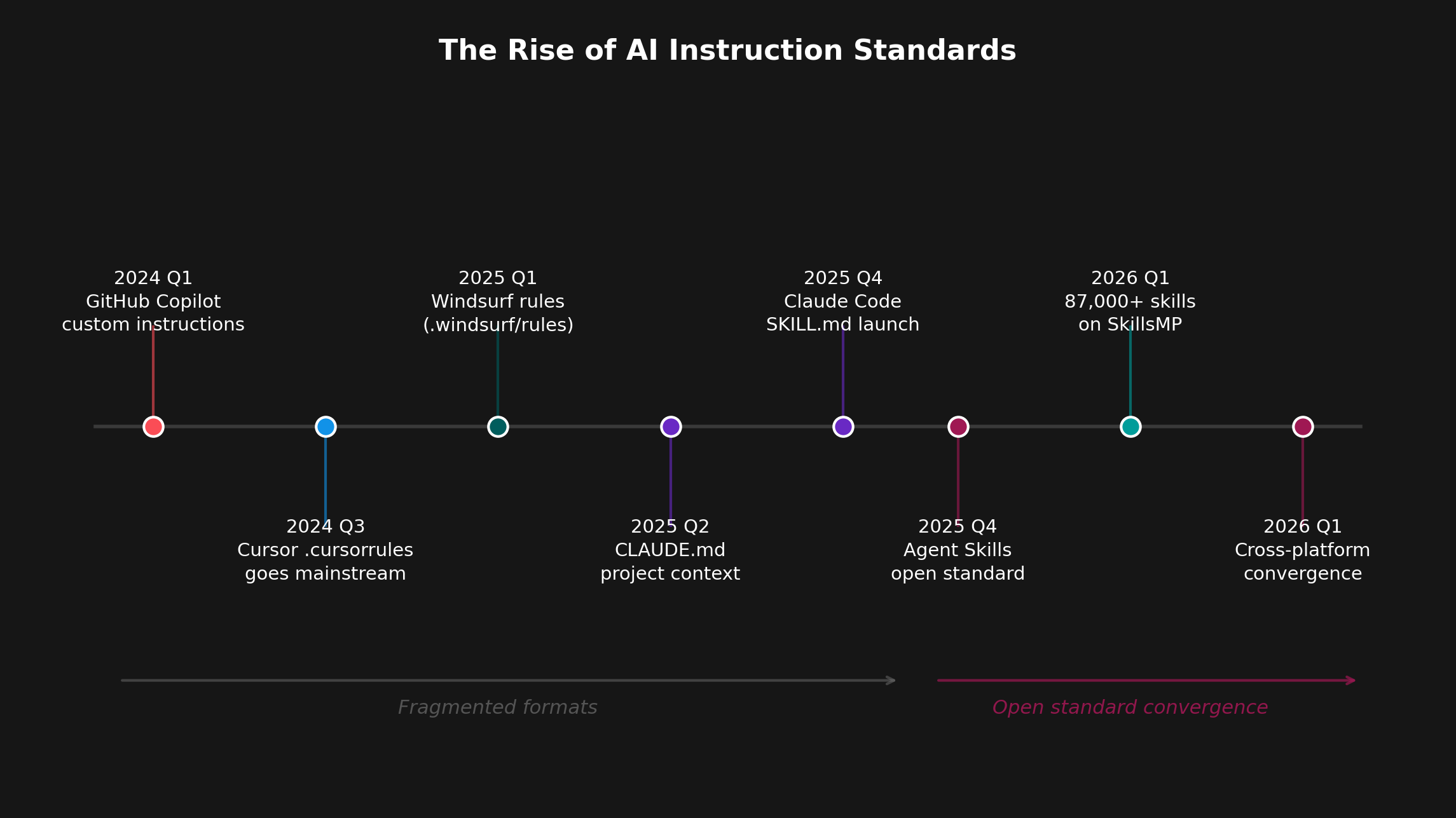
In December 2025, Anthropic released the Agent Skills specification as an open standard, and the industry converged within weeks. OpenAI adopted it for Codex, Microsoft integrated it into Copilot, and every major AI code editor (Cursor, Windsurf, Claude Code) now supports SKILL.md files alongside their legacy formats. The SkillsMP marketplace — a public index of reusable skills — now contains over 80,000 skills created by developers worldwide.
The gap between "AI helps me code" and "AI helps my team ship" is no longer a mystery. It's a grounding problem — and it has a solution.